
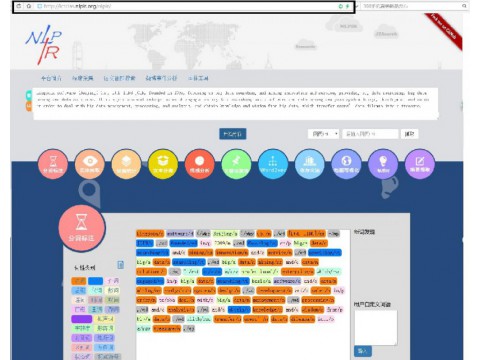




The main functions include Chinese word segmentation; English tokenization; Part-Of-Speech (POS) tagging; named entity recognition; new word identification; keywords extraction; and supporting user-defined lexicon. The NLPIR system is compatible with all encoding including GBK and UTF-8, all operating systems including Windows, Linux, Android and IOS and can be invoked by all programming languages such as Java, Python, C and C#.
Word segmentation for both Chinese and English
Automatic tokenization and POS tagging for both Chinese and English. Detail functions are: Chinese word segmentation, English tokenizaiton, POS tagging, unknown words recognition and supporting user-defined lexicon.
Keywords extraction
We use information entropy algorithm to extract keywords , including listed and unlisted words. The following keywords is automatically extracted from the political report in the 3rd Plenary Session of 18th CPC Central Committee.
New words identification and Adaptive Word Segmentation
New Words is identified using information entropy from given regular untagged texts. Then new words are added to train language modeling and adapted to make adaptive segmentation.
User-defined Lexicon Supported
User-defined words can be added to NLPIR system one by one. They can be also batch imported. User-defined lexicon will refine the final segmentation results with a real-time speed.